DOING MORE WITH LESS: IMPROVING ROBUSTNESS USING GENERATED DATA 리뷰
21 Jun 2021
Reading time ~3 minutes
Abstract
- Robust한 학습을 하기 위해서 단순히 classification을 위한 데이터 이상의 더 많은 데이터가 필요한 것이 정설이다.
- CIFAR-10, CIFAR-100에서 80M-TI를 사용한 것과 그렇지 않은 경우 사이에는 큰 Robust Acc의 갭이있다.
- 저자들은 SOTA 생성 모델을 활용하여 인공적으로 원래 데이터셋의 크기를 증가시키고 \(\ell_{p}-\text{norm}\) bounded perturbation에 대한 adversarial robustness를 증가시키는 방법을 탐색했다.
- 이 방법으로 저자들은 추가데이터를 사용한 모델과의 robust accuracy 갭을 상당히 줄였으며 심지어 랜덤 데이터를 활용해도 robustness를 증가시킬 수 있다는 것을 보여주었다.
💡 \(\ell_p-\text{norm}\) bounded perturbations 이란?
- 쉽게 말하면 원본 입력과 perturbation이 적용된 입력의 차이의 \(\ell_p\) norm 이 \(\epsilon\) 보다 작도록 bounded 되었다는 뜻이다. 이런 adversarial example을 만드는 방법은 FGSM, PGD 등이 있다.
Introduction
- 딥러닝 모델이 입력의 다양한 perturbation에 robust하는 것은 중요함
- 데이터에 사람은 인식할 수 없는 adversarial perturbation를 더했을 때 모델이 잘못된 예측을 할 수 있다.
- 이를 해결하기 위해 많은 방법이 제안되었고 추가적인 데이터를 사용하는 것은 큰 효과를 보였지만 추가 데이터를 사용하지 않는 면에서는 진전이 더디다.
-
저자들은 원래의 training set만 가지고 확장하여 문제를 해결할 수 있는 방법을 찾아보았다.
- 저자들이 말하는 이 논문의 기여는 다음과 같다.
- 질이 낮은 랜덤 입력으로도 robust accuracy를 높일 수 있다는 것을 보여주었다.
- 원래 학습 데이터를 이용해 학습된 생성모델(DDPM, VDVAE, BigGAN)의 질 좋은 입력을 이용하는 방법을 찾았다.
- DDPM을 사용해서 기존 SOTA보다 6.44% 높은 robust accuracy를 얻었다. 또한 이 논문의 best CIFAR-10, CIFAR-100 모델은 하나를 제외한 모든 추가 외부 데이터를 사용한 기법들을 이겼다.
Method
Motivation
- Data augmentation은 평범한 학습에서 모델의 일반화 오류를 줄이는 데는 효과적인 것으로 보인다.
-
하지만 random flip, crop, rotation같은 기법 이상의 Cutout, mixup, AutoAugment, RandAugment같은 기법들은 adversial training에서는 성공적이지 못했다.
- 추가적인 데이터를 사용한 모델과 그렇지 않은 모델의 robustness gap은 본질적으로 원래와 비슷한 이미지를 생성하는 augmentation 기법의 한계를 보여준다.
Hypothesis
- 저자들은 robustness를 개선하기 위해서는 더욱 다양하고 원래의 training set을 보완할 수 있는 augmentation이 필요하다는 가설을 세웠다.
- 가설을 검증하기 위해 학습 데이터의 class-conditional 가우시안 fit으로부터 생성된 샘플을 사용했다.
-
결과적으로는 아래 그림과 같이 50% ~ 90% 비율로 원본데이터를 사용하고 나머지는 생성된 데이터를 사용했을 때 robust accuracy가 증가했다. (최대 0.93%)
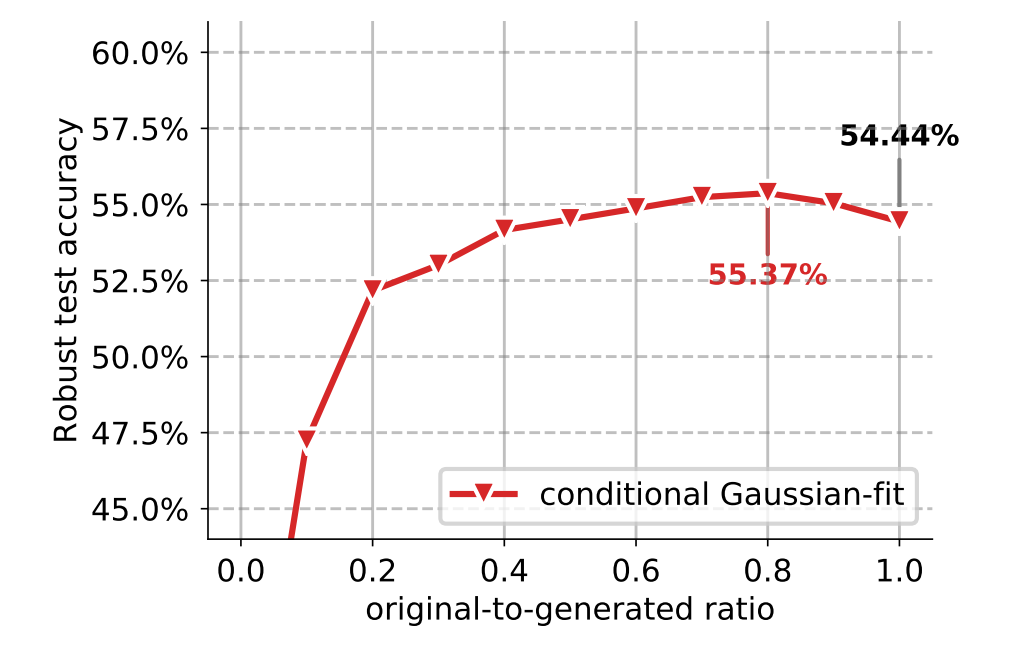
- 위 결과로 생성모델로 만든 데이터는 훨씬 효과가 좋을 것이라 생각하고 VDVAE, BigGAN, DDPM 생성 모델을 이용해 실험했다.
-
CIFAR-10 학습셋을 이용해 학습한 모델로 이미지를 생성한 뒤 각각의 생성된 이미지의 LPIPS feature space에서 nearest neighbor가 train set, test set, 생성한 데이터셋 자체 중에서 어디와 가장 비슷한 지 를 확인했다. (이상적인 생성모델이라면 각 비율이 고르게 나와야할 것이다)
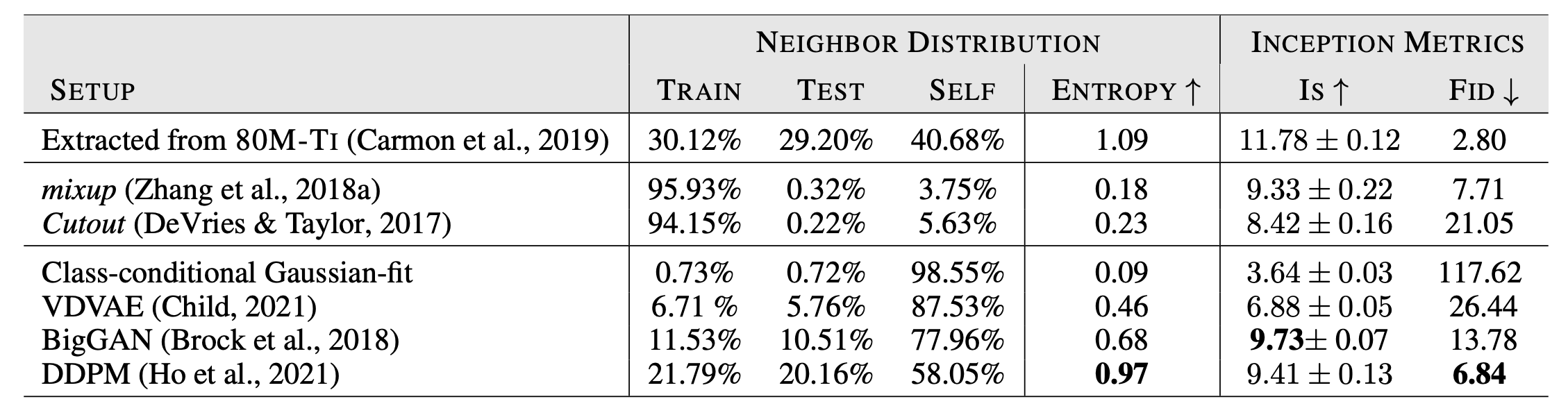
확인 결과 일반적인 Augmentation 방법들은 train set과 비슷한 이미지를 생성하는 비율이 매우 높았다. 이는 train set을 보완할 능력이 부족함을 뜻한다.
또한 VAVE, BigGAN은 생성한 셋 자체에 nearest neighbor가 있는 경우가 많았는데 이는 실제 데이터와 동떨어진 이미지를 많이 만들거나 비슷한 이미지만 생성한다는 뜻으로 볼 수 있다.
DDPM이 80M-TI 외부 데이터를 사용했을 때의 분포와 가장 비슷했다.
Experimental Results
- 실험에는 TRADES를 비롯한 adversarial training 기법들을 사용했다.
Mixing ratio
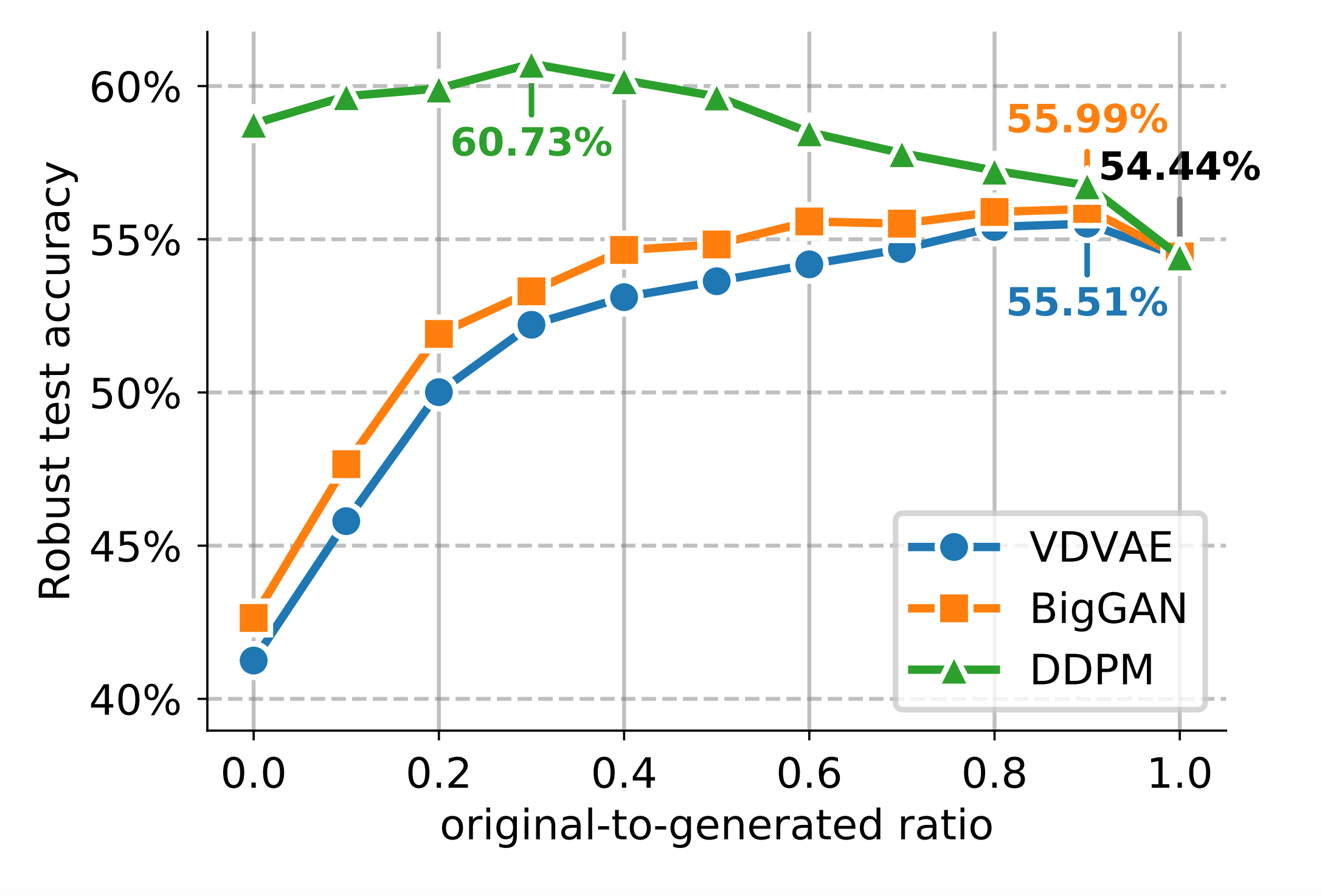
- 랜덤 데이터 때처럼 원본 데이터와 생성된 데이터의 비율을 조정하며 robust accuracy를 측정하였다.
- 모든 경우에서 생성된 이미지가 적절한 비율로 섞이면 robust accuracy가 증가했다. 하지만 DDPM을 사용했을 때는 생성된 심지어 1M의 생성된 이미지만 사용했을 때도 원본 50K 데이터만 사용했을 때보다 robust accuracy가 높았다.
- DDPM은 최적의 경우, 원본데이터만 사용했을 때보다 +6.29% 성능 향상을 보였다.
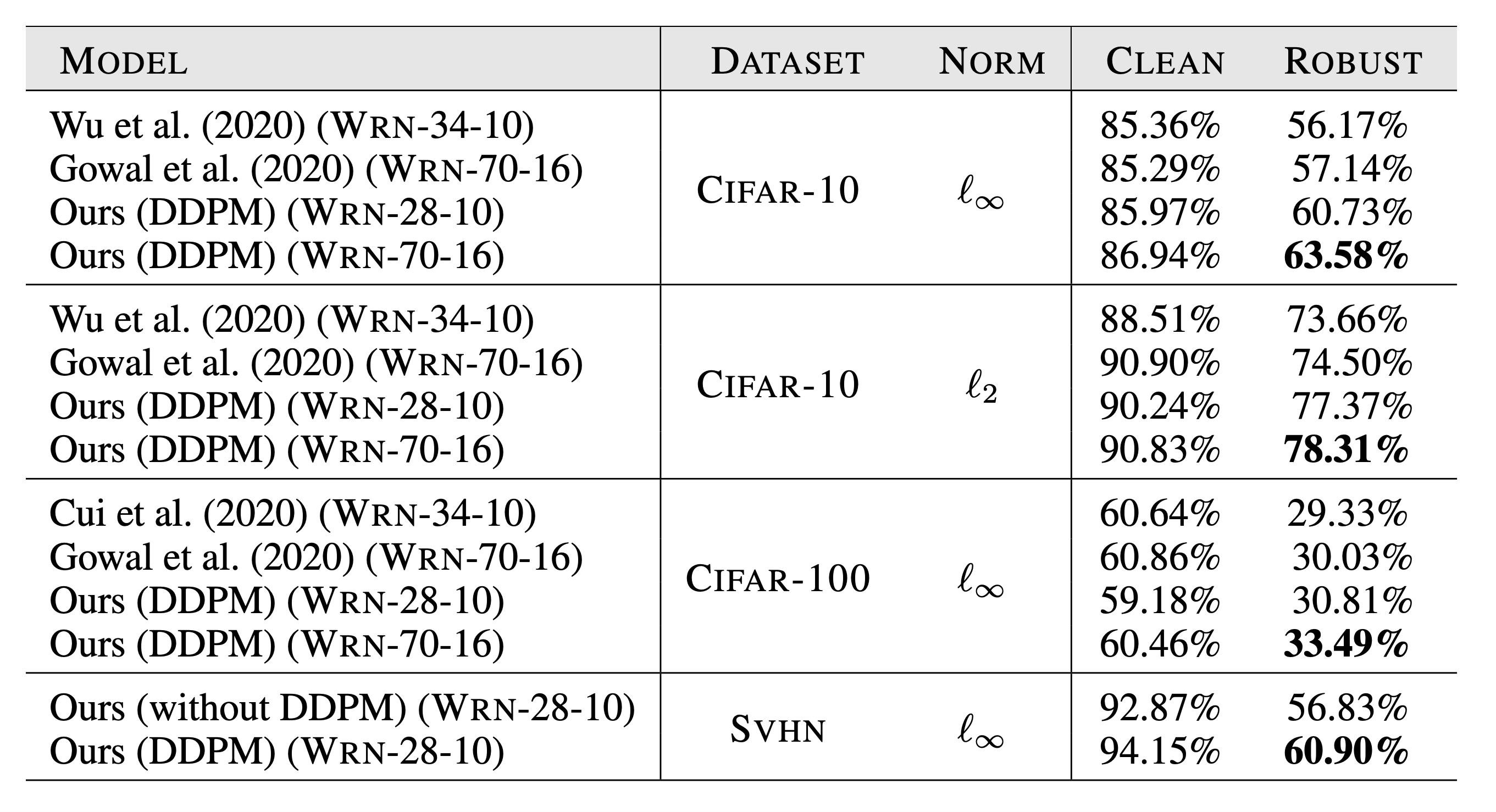
- CIFAR-10, CIFAR-100, SVHN에서 DDPM를 사용한 모델은 전체적으로 큰 robustness의 향상을 보였다.
Conclusion
- 저자들은 생성 모델을 이용한 다양한 샘플을 만들어 adversarial training이 효과적으로 동작함을 보여주었다.
- 이 연구는 diversity와 complementarity가 robustness에 미치는 영향에 대한 신선한 통찰을 보여주어 robustness에 대한 더 높은 이해를 제공했다.