Convolution을 이용한 간단한 한국어 띄어쓰기 교정 모델입니다. 속도를 우선으로 고려하였습니다. 아래에서 바로 사용해보실 수 있습니다. 이 데모의 모델들은 모두의 말뭉치 국립국어원 문어 말뭉치(버전 1.0) 데이터를 이용하여 학습한 모델입니다.
파이썬으로 설치해서 사용하고 싶으시거나 더 자세한 사항은 Quickspacer 레포지토리를 참고해주세요.
Level은 1,2,3 세 종류가 있으며 Level이 높을수록 일반적인 띄어쓰기 성능이 높지만 더 추론이 오래걸립니다. 버튼을 눌러보면 시간이 왜 이리 오래 걸리지 싶으실 수 있는데 웹에서 Javascript로 돌리는 것을 감안해주시면 좋겠습니다. (파이썬으로 설치해서 사용하거나 Tensorflow Serving으로 serving하면 당연히 훨씬 빠릅니다.)
본 모델은 띄어쓰기를 추가하는 기능만 있기 때문에 띄어쓰기를 없앨 필요가 있다면 그냥 띄어쓰기를 모두 없앤 상태에서 띄어쓰기 하시면 됩니다. Remove Spaces버튼으로 띄어쓰기를 모두 없앨 수 있습니다.
Demo

Inference Speed
파이선 패키지로 QuickSpacer를 설치하고 키다리 아저씨 텍스트(496kb, 4149 lines) 각각 level 1,2,3 의 속도를 재보았습니다.
(테스트환경: 맥북 프로 2019 2.6 GHz 6-Core Intel Core i7 CPU)
| Level | 전체 소요 시간 (seconds) | 문장 당 소요 시간 (milliseconds) |
|---|---|---|
| Level1 | 2.06276989 | 0.4971727862 |
| Level2 | 11.51787686 | 2.7760609448 |
| Level3 | 21.18218493 | 5.1053711569 |
위 시간은 전부 파이썬에서 List[str]로 문장을 넘기고 다시 띄어쓰기가 된 문장을 List[str]형태로 받기까지의 end-to-end 시간입니다. 결과는 위와 같은 속도를 보였으며 기대했던 만큼 빠르지는 않은 것 같습니다. 다만 BatchSize나 문장의 최대 길이 등에 따라 병렬 연산 처리나 Padding의 정도가 달라져서 속도에 차이가 있을 수 있습니다.
이 속도로 소요시간이 파일 용량에 정비례한다고 가정했을 때 1GB 데이터셋을 띄어쓰기하는데 Level1은 73분, Level2는 약 7시간, Level3는 약 12시간 반이 걸립니다.
(좀 더 가볍게 만들어봐야 될 듯…)
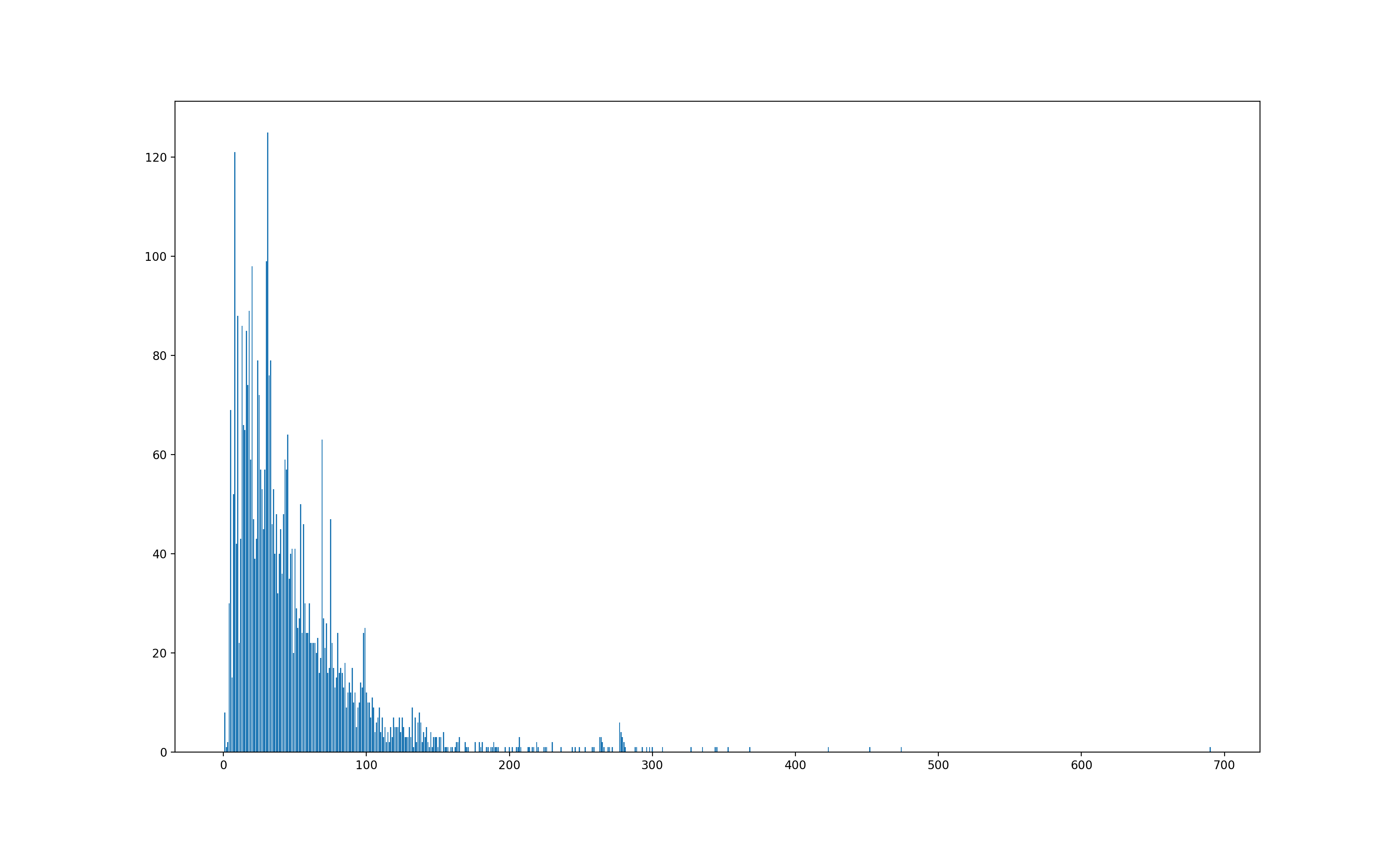
패딩이 얼마나 낭비되는 지 보기 위해 문장의 길이를 그래프로 그려보았습니다. 보면 대부분의 문장은 100보다 한참 아래, 한 30 부근에 위치해 있습니다. 그런데 최대로 긴 건 700부근에 하나 있고 400에서 500사이에도 몇 개가 있습니다. 그렇다면 30짜리 문장들이 PAD를 대충 470개 이상 달고 추론을 했다는 뜻이 될 것입니다. 낭비가 좀 심하네요. 그래서 다시 한 번 실험을 해보았습니다. 저 키다리 파일을 문장의 길이가 128이 넘어가는 경우는 다음 줄로 넘긴 것입니다. 파일의 용량은 452kb로 줄었습니다.(압축을 하나?) 총 글자수는 \n 때문에 201756->202007로 분명 좀 더 늘었고 line의 수도 4400로 조금 늘었습니다.
그런데…
| Level | 전체 소요 시간 (seconds) | 문장 당 소요 시간 (milliseconds) |
|---|---|---|
| Level1 | 1.23759389 | 0.2812713386 |
| Level2 | 4.12937498 | 0.9384943136 |
| Level3 | 7.08049107 | 1.6092025159 |
속도가 엄청 빨라졌습니다. 역시 PAD 때문에 낭비되는 연산이 많았다는 뜻이네요. 이 글을 보고 사용하시는 분들은 이 점을 고려하면 많은 도움이 될 것 같습니다.
키다리 아저씨 출처: 여기서 빈 행만 없애고 사용했습니다.